Work in progress: Portraits of Imaginary People
For a while now I’ve been experimenting with ways to use generative neural nets to make portraits. Early experiments were based on deepdream-like approaches using backprop to the image but lately I’ve focused on GANs. As always resolution and fine detail is really difficult to achieve. For starters the receptive field of thse networks is usually less than 256x256 pixels. One way around this is tiling combined with stacking GANs, which many people have experimented with, for example this paper uses a two-stage GAN to get high resolution: (https://arxiv.org/abs/1612.03242).
I tried a similar approach and I’ve been finally been having some more success upres-ing GAN-generated faces to 768x768 pixels in two stages and in some cases as far as 4k x 4k, using three stages. This gives them a lot more crisp detail. Since I’m trying to do this with art in mind, I don’t mind if the results are not necessarily realistic but fine texture is important no matter what even if it’s surreal but highres texture.
{kind=link}
As usual I’m battling mode collapse and poor controllability of the results and a bunch of trickery is necessary to reduce the amount of artifacts. Specifically the second stage GAN is meta stable between smooth skin and hairy skin and often results in patchy output. For now I’m using vanilla GANs and these results are fairly cherry-picked - I should give WGAN, CramerGAN or BEGAN a shot, word is they converge better. BEGAN seems to have a smoother, VAE kinda look which perhaps makes sense because the discriminator is an auto encoder and the loss is an indirect reconstruction loss.
Anyways, here are some highly cherry-picked work-inprogress results:



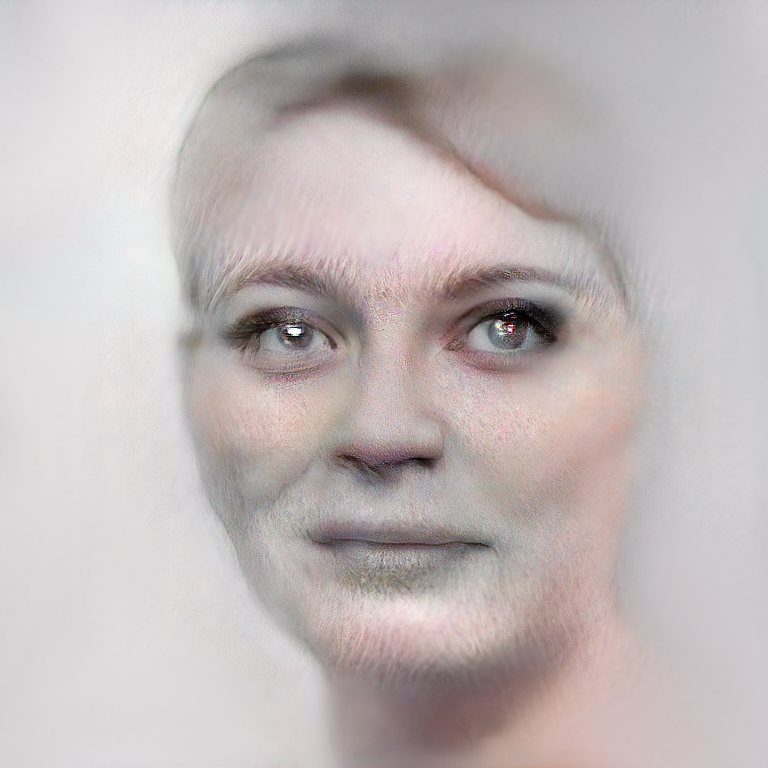






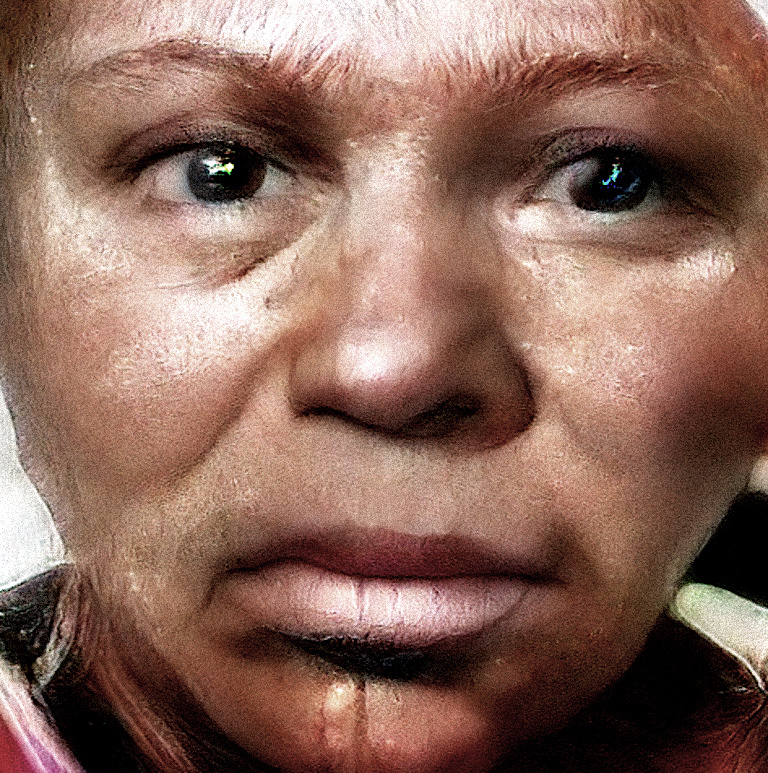



The quality depends strongly on the realism of the lowres output. I typically generate things at 128x128 or 256x256 at the first stage and then upres to 768x768 or 1024x1024 at the second stage. In most cases the quality is nowhere near the above, but in some cases the results are kinda interesting artistically. Occasionally a sort of artistic style emerges.





Adding a third stage allows upressing up to 4k. However I dont have any actual training data at that resolution, meaning the network only learns to generally predict smooth edges etc, It can’t know the details of what skin pores or eyelashes look like. A super-highres database of faces would be needed here. Still for purposes of printing it’s nicer to create some interesting looking artifacts at this resolution, rather than bilinear interpolation of just pixelation.


Some full size 4k ones (click to enlarge):


Anyways, the goal is to make these into printable physical-world art pieces but I found in practice the resolution and detail has to be pretty high or it just doesn’t look nice printed. Like I said, it’s all work in flux and progress, more soon.
Followup: Method
By popular request a little more on the approach taken here.