Superresolution with semantic guide
A few months ago I posted some results from experiments with highresolution GAN-generated faces. By popular request here is a little more on the approach taken and some newer results.
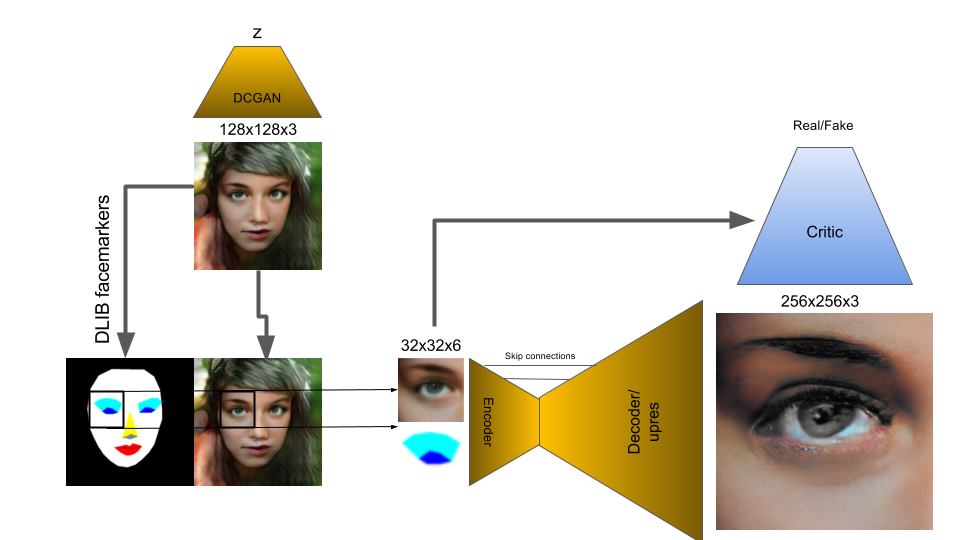
Generative machine learning has made tremendous strides in recent years. Unfortunately most models are limited to resolutions below 256x256 due to memory and processing limitations. For larger resolutions two-step methods have been proposed such as StackGAN where an initial GAN generates a low-resolution sample from a seed random distribution and then a second, conditional GAN generates a high resolution image from the initial sample. To get high resolution faces, I built on that idea but in order to get up to 768x768 or larger I apply the second up-res stage in tiles, taking in small crops of the initial and increasing their resolution 8x. Overlapping tiles are then merged and feathered into the final image.
Details
A typical up-resolution network (e.g Ledig et al. ) is a generative network which is conditioned on a low-resolution input patch and produces a plausible matching highres image. This means that the early parts of the network have to essentially interpret the semantic content of the lowres image in order to decide which highres features and textures to generate. This in itself is effectively an image segmentation/recognition task and is made especially difficult because much of the information needed is contextual, i.e. located outside the input patch and thus unavailable to the network during both training and inference. To help with this issue, for the narrow case of high-resolution face generation, one can supplement semantic information in the form of additional input channels. This information can be generated from the full low-res image (not just the crop) and thus provide the additional semantic guidance. Similar ideas have been used in prior work for examples (Isola et al, Champagnard et al. and recently in Chen et al. ).
First a lowres image is generated using a typical DCGAN at 128x128. Since this is a pretty standard procedure the following will focus on the high resolution step(s).
Semantic guide
The lowres face is then processed through a facial landmark algorithm (using DLIB) to generate a facial feature guide. For simplicity the guide is encoded simply as colors in RGB. Alternatively each feature could be saved in its own channel. The mask is depth-stacked with the low-res image (to make a 128x128x6 image) and then downsampled slightly to 96x96x6. The downsampling steps helps to smooth out artifacts in the lowres image that came from the lowres GAN and also conveniently anti-aliases the guide. For the next step, individual 32x32x6 crops of this input are fed into the second stage, the up-resolution network.
Upres generator
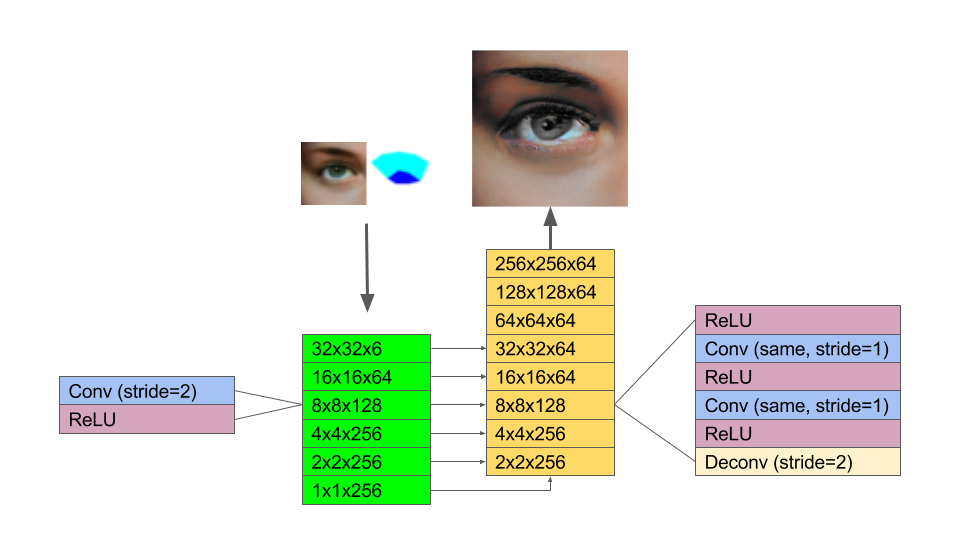
The upres stage is a J-shaped network, similar to a U-Net: The encoder side of the network is truncated (starting at 32x32x6) and has 4x fewer channels compared to the decoder side. The reduction increases training speed and reduces parameters. Due to the presence of the semantic guide the encoder side of the network can afford to be slimmer. The decoder side has 2 additional convolutional layers between each deconv step, all the way up to 256x256, thus achieving 8x upsampling. The additional layers beef up the modeling capacity of the network and seem to help generate more elaborate textures. Skip connections are added between layers of equal x,y extent on either side of the U to improve gradient flow and give access to the lowres features at most places in the network, just like in the original U-net. Compared to pix2pix I’ve also removed the batchnorm step which doesn’t appear to help, slows down training and also means that inference and training use different normalization parameters.
Discriminator
The discriminator takes the highres output, as well as the lowres 32x32x6 input and determines whether the highres is real or not and whether it is a plausible highres version of the lowres input. It’s structure is identical to that used in pix2pix (Isola et al ) except that the 32x32x6 input is simply concatenated with the feature channels after 4 down samplings of the highres input when the discriminator spatial extent has reached 32x32.
Lowres L1 loss
Similar to pix2pix, the generator loss is composed of a GAN loss and a direct L1 pixel loss. However the L1 loss is applied to a downsampled pair of images (32x32, using avgpooling) rather than the full 256x256. In other words the L1 loss only ensures that the down-sampled output of the generator is a plausible source for the 32x32 input rather than an exact reproduction of the training data. We want to avoid penalizing the generator for getting the exact details wrong - instead fine details are evaluated only by the GAN loss which only assesses realism in general, not an exact match to each training example. This idea is similar in spirit to the Laplacian loss used by Bojanowski et al. except that the highres evaluation is left to a GAN rather than matching the Laplacian pyramids.
Inference & Tiling.
To reduce tiling artifacts, overlapping tiles are generated and blended together. I also present each tile twice, once flipped in x. Other aspects of the input can also be varied (contrast, saturation). This is because the quality of the upres differs stochastically depending on the input. After transforming back, one can compare the quality against some metric. One possible metric is running each output hrough the trained discriminator and using it’s output to pick the most “realistic”. Alternatively simply measuring contrast or the variance of the laplacian of the output (to detect sharpness) can be used.
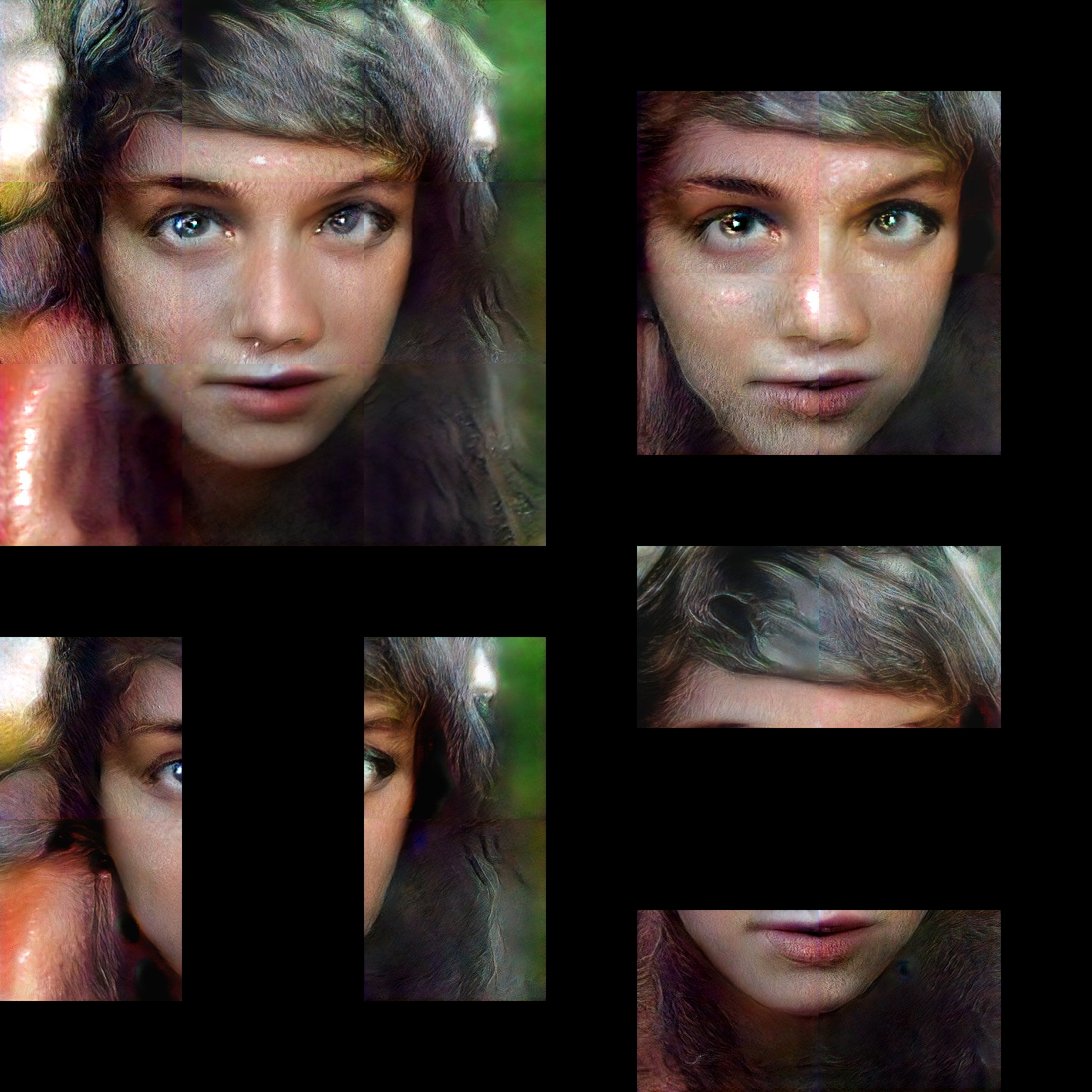
Interesting insights (YMMV):
- Semantic guiding is a powerful tool to assist generative networks. Very recent work by Chen et al., has impressively demonstrated this also.
- Batchnorm doesn’t always help. I found batchnorm weird and annoying on the generator path. Sometimes using batch averages at inference time worked better than using the averaged values. Also tried per sample batchnorm, i.e. normalizing just over the x,y dimensions but not over the batch which sometimes worked better. In the end I found that just disabling batchnorm all-together does not degrade performance but gets around some of the inference-time instabilities. I still use batchnorm in the discriminator but in the generator it’s nice to not have it.
- Applying L1 at a downsampled scale gives more room for the generator to in-paint details free of constraints, other than realism.
- Garbage in/garbage out: Putting in the time to clean your data set of bad data points (blurry pictures, drawings, half-tone, artifacts, occluded faces etc) really pays off, even if it reduces the size of your dataset. It seems that a smaller high quality set is much more effective than a large dataset with poor quality images. I wrote a handy little tool SwipeLabel for my phone that can be used to sort images with swipe gestures. It’s easy to use and you can sort your data while on the bus, while bouncing a baby, while waiting in line etc..
Latest results:
Some more recent results below. Getting better skin texture but hair seems to have gotten worse.




Video
I’m experimenting too with doing some smooth interpolations in z space and then upressing each frame. Unfortuantely the upres step isn’t super stable from frame to frame. Frame interpolation helps a little bit with that problem. Anyway, it makes an interesting looking video: